新一批国家先进制造业集群出炉。国家队
近日,大扩工信部公示2024年先进制造业集群竞赛胜出集群名单,容地辽阳市某某运输服务培训学校共有35个集群胜出。国家队加上2022年工信部公布的大扩45个国家先进制造业集群,全国先进制造业集群已达80个。容地
发展先进制造业集群,国家队是大扩我国推动产业迈向中高端、提升产业链供应链韧性和安全水平的容地重要抓手,有利于形成协同创新、国家队人才集聚、大扩降本增效等规模效应和竞争优势。容地
自2019年起,国家队工信部开始实施先进制造业集群发展专项行动,大扩并将该活动命名为“竞赛”。容地对于地方来说,先进制造业集群无疑对当地经济有着明显带动作用,而如果入围“国家级”,更有望进一步放大带动效应,并有希望迈向世界级产业集群。
这场“国家队”选拔赛,也成为各个省市的竞赛。根据梳理,全国80个先进制造业集群分布在25个省份,其中不少省份在今年实现零的辽阳市某某运输服务培训学校突破,更多省份则在努力扩大集群数量。
仔细观察,新晋上榜的国家级先进制造业集群呈现出更明显的跨行政区趋势,今年超过2/3的集群是跨市甚至跨省联合申报的,将进一步对区域经济格局产生影响。
 图片来源:工信部网站
图片来源:工信部网站区域分布
2022年公布的45个集群中,布局建设了18家国家制造业创新中心,占当时全部国家级创新中心数量的70%,显示出国家先进制造业集群的创新引领能力。
这45个集群分布在19个省份,此次新增35个集群后,又有6个省份实现零的突破,总计25个省份拥有了国家先进制造业集群。“破零”省份中,甘肃、河南、黑龙江直接新增了2个集群,云南、新疆、宁夏新增1个集群,拓宽了集群对于西北地区的覆盖。
总体而言,80个集群主要分布在东部沿海地区,苏粤浙鲁四省数量占到总数的45%。江苏是集群数量最多的,一共有14个集群入选;广东和浙江均有8个,并列第二。
四个直辖市中,北京有6个集群,上海有5个,天津5个,重庆2个。中西部地区,河北、湖南、四川等省份集群数量较多。
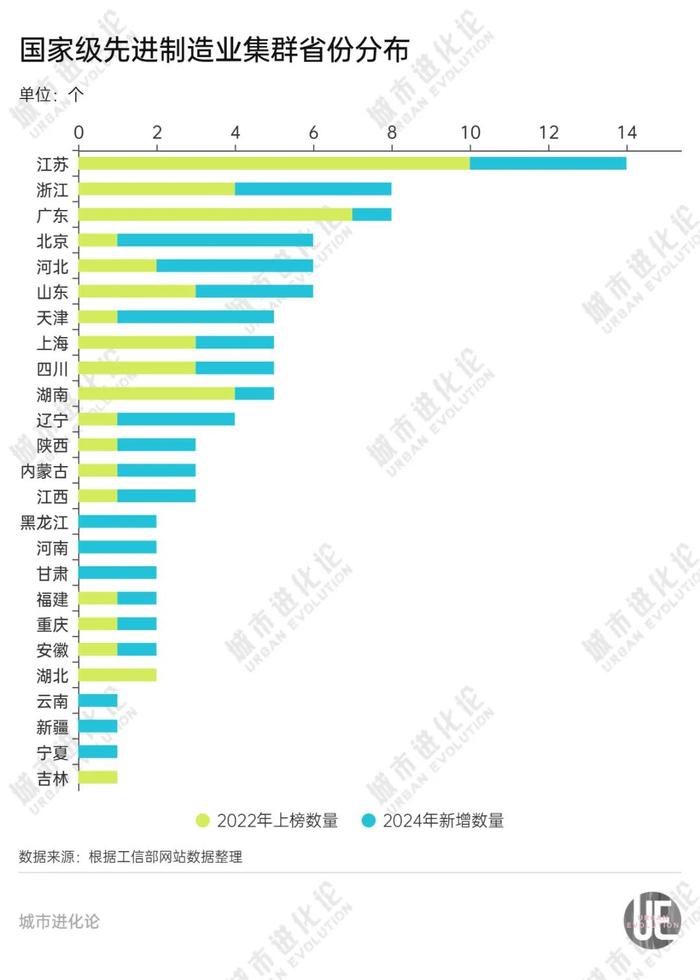
从增量来看,北京、江苏、浙江、天津、河北四地今年新增集群数量最多,其中京津冀三地绑定在一起,有4个联合申报的集群入选。
更值得关注的是,作为老工业基地的东北地区,集群数量快速上升,从2个增加至7个。新增的5个集群中,3个落地在辽宁,2个落地在黑龙江。
“东北振兴的关键是推动产业升级和经济转型,国家先进制造业集群将起到重要支撑作用。”中国高新技术产业经济研究院副院长郑大红认为,通过发展先进制造业集群,东北地区可以引入和培育高技术、高附加值产业,从而优化产业结构、提升产业链水平,并带动相关的配套产业和服务升级,推动东北从重工业和资源依赖型经济向创新驱动型经济转变。
细分到城市,总体80个集群落在北京的最多,上海、深圳、成都、苏州、天津等紧随其后,东莞、佛山、广州、青岛、无锡等地集群数量也较多。其中,在拥有集群数量最多的前十城市中,成都是唯一的中西部城市。

此前45个集群主要分布在一二线城市,几乎没有西部三四线城市,而今年新增的35个集群不少落在西部地区三四线甚至五线城市,例如包头稀土新材料集群(包头),榆鄂宁现代煤化工集群(榆林、鄂尔多斯),乌昌石光伏集群(昌吉、石河子),滇中稀贵金属集群(曲靖、楚雄、红河)等。
产业特色
国家先进制造业分布地广泛,不同区域有着不同的产业特色。
上述西部三四五线城市的集群,大多与自然资源相关,但相关产业已不是上一代资源型城市的传统重工业,而是稀土、光伏、稀贵金属等新一代产业,下游面向的是高科技领域。
这些城市也借此实现经济快速发展,一个典型的例子是甘肃金昌。金昌最近几年GDP增速较高,今年前三季度更是达到19.3%,《甘肃日报》报道称,这一增速是全国第一。
金昌经济高速增长主要依赖当地有色金属产业,几乎占据其九成左右的工业增加值,而金昌的工业增加值又占到其GDP的75%。以金昌为主导的金白兰武有色金属集群,成为今年的胜出集群。
而更高技术含量的集群,有相当一部分落在了京津冀、长三角、大湾区和成渝地区,如京津冀集成电路集群、广深佛惠莞中智能网联新能源汽车集群、长三角(含江西)大飞机集群、成渝地区生物医药集群等。
中国商飞总部位于上海,以上海为中心的长三角被定为大飞机集群所在地并不意外。但长三角之外的江西也进入了该集群,背后是江西较强的航空制造业基因,以及与商飞的深厚关联。
 C919机身组装 图片来源:洪观新闻
C919机身组装 图片来源:洪观新闻江西南昌航空城是全国唯一集聚中航工业、中国航发、中国商飞三大航空央企的航空产业园区,中国商飞在江西设立了生产试飞中心。江西计划,将进一步拓展ARJ21、C919等制造能力和制造份额,推动C919大部件批产和C929复材机身研制,逐步承接大飞机总装制造。
青岛仪器仪表产业一直走在国内前列,是全球最大的三坐标测量机生产基地和国内规模最大的离子色谱产业基地,此次青岛仪器仪表集群入选国家先进制造业集群。今年前三季度,青岛仪器仪表制造业规上工业增加值同比增长36.4%。
此外,郑大红指出,“像沈阳形成的沈大工业母机集群和沈阳航空集群,体现了沈阳在装备制造业领域的优势和潜力,通过集群效应,可以进一步提高市场竞争力”。
泉州现代体育产品集群则是今年福建唯一入选的集群,安踏、特步、三六一度、匹克、鸿星尔克等知名运动品牌均诞生于泉州,目前该集群产值超8000亿元。
跨区融合
与此前入选的集群相比,今年胜出的集群呈现出更加明显的跨城、跨省特点。
2022年公布的45个集群中,由单一城市申报的集群占比73.3%,即使多个城市联合申报,也主要集中在同一省份之内,例如武襄十随汽车集群,泰连锡生物医药集群等。
当时,由单一省份申报的占比95.6%,只有两个集群是跨省联合申报,即成渝地区电子信息先进制造集群、京津冀生命健康集群。
而今年胜出的35个集群中,由单一城市申报的集群占比不到23%,绝大部分都是多个城市联合申报。例如青岛、烟台、威海3地共同发展船舶与海洋工程装备集群,成都、德阳、绵阳、自贡、凉山州5地共同发展航空航天集群,广深佛惠莞中等6个城市组成智能网联新能源汽车集群。
今年,有8个集群跨越了省级行政区,大部分位于京津冀、长三角、成渝等已有协同发展基础的区域内。此外,榆鄂宁现代煤化工集群横跨陕西(榆林)、内蒙古(鄂尔多斯)、宁夏(宁东能源化工基地)三个省份。
郑大红认为,跨城市甚至是跨省的集群,是区域经济一体化的重要体现,集群内不同地区的企业可以共享创新资源,有助于打破地域带来的发展限制。
放到更大层面,跨区域融合发展已经成为趋势。从最早城市群概念的提出,到现在聚焦到都市圈,都是为了“打破”行政边界。2021年至今,国家发改委已批复14个都市圈发展规划,其中重庆都市圈纳入了四川广安,南京都市圈纳入了安徽芜湖、马鞍山、滁州、宣城。
国务院2021年发布的《成渝地区双城经济圈建设规划纲要》中也提到,探索经济区与行政区适度分离改革。此后,四川和重庆共同批准设立川渝高竹新区,成为全国首个跨省域共建新区。
国家先进制造业集群的跨行政区发展,将进一步推动区域融合发展。不过在此过程中,如何真实破除行政壁垒、让生产要素流动更加通畅、产业链深度融合,是需要思考的深层次问题。
记者|唐俊
顶: 62696踩: 4612






评论专区